
Seven Million Pages Nobody Can Read: The State of Icelandic OCR
2 June 2026Introduction
Iceland has around 350,000 native speakers and roughly seven million scanned pages of historical newspapers and periodicals sitting on public servers at Tímarit.is 1. The text on those pages has been machine-read by OCR engines. Much of it is wrong, and for a significant portion of the archive, particularly periodicals printed in fraktur type, it is effectively unreadable.
This post surveys the existing research. Most of it covers post-OCR correction (taking flawed machine output and cleaning it up with a second model) rather than improving the recognition system that produces the errors in the first place. The one recognition engine the field actually uses, Tesseract trained on Icelandic Wikipedia text, has never been evaluated on any Icelandic test set. And there is no public image–text benchmark that would make such evaluation possible.
I'll cover what the digitization infrastructure looks like, what the post-correction literature has achieved, where the recognition layer stands, and what's missing.
What makes Icelandic OCR distinctive
Character set
Icelandic uses the Latin alphabet plus four characters that generic OCR engines tend to misread: Þ/þ (thorn), Ð/ð (eth), Æ/æ, and accented vowels (á, é, í, ó, ú, ý). Jasonarson et al. extracted error statistics from 375k tokens of manually corrected 19th-century text and reported p being confused with þ 2,779 times, i being confused with í 1,141 times, and rn being confused with m 166 times — figures MC-19 subsequently reproduced when checking approximately 400 titles from the same archive.23. Recent multilingual benchmarking of VLMs finds the same confusions persist in current recognition systems, not just in Tesseract. Kargaran et al. note that models trained predominantly on English frequently confuse þ with p and ð with d.4. Errors of this kind are systematic and learnable, a model trained on enough Icelandic text should handle them reliably on clean modern print.
Morphology
Icelandic is heavily inflected: four cases, three genders, and rich compounding produce dozens of valid surface forms per lemma. The practical consequence for OCR is that a single misread character often produces a different valid Icelandic word rather than a typo. A 2012 thesis on post-correcting digitized Icelandic parliamentary records distinguishes two error categories:5
- Non-word errors: misreads producing strings that are not valid Icelandic. Standard spell-checking handles these.
- Real-word errors: misreads producing different valid Icelandic words. Spell-checking is blind to these; correction requires context.
The real-word category is unusually large for Icelandic because the inflectional system fills the word space densely.
Historical material
Older print degrades from dust, grime, and yellowing in ways that compound character segmentation errors; the same documents also use archaic orthography that a model trained on modern Icelandic has to handle simultaneously.
CEMI, a corpus project on 1540–1850 manuscripts and printed books treats OCR error correction and spelling normalization as separate pipeline stages.6 A model trained on modern Icelandic text effectively has to do both jobs simultaneously on historical input.
Fraktur (also called blackletter or Gothic script) is a dense, angular typeface used in Icelandic religious and official print through the early 20th century. Its ornate letterforms and ligatures share little visual vocabulary with the standard Latin fonts that OCR engines train on. Steingrímsson et al. checked all fraktur-printed periodicals in the 1800–1920 Tímarit.is archive and found every one of them effectively unusable. MC-19 does not name the OCR engine, but Jasonarson et al. identify the Tímarit.is OCR output as produced by ABBYY FineReader.23

The two-problem split
It's worth being explicit that "Icelandic OCR" covers two largely separate research programs:
- Printed text OCR: Recognition of text from print (ranges from typewriters to digital printers)
- Handwritten text recognition (HTR): Recognition of text from handwriting (think of handwritten letters, journals, etc.)
Most Icelandic OCR work I cite below deals exclusively with printed text. The two streams use different tools, different datasets, and different metrics, and progress on one doesn't transfer cleanly to the other.
Digitization infrastructure
The data substrate is unusually good for a small language, with one important caveat about access.
| Resource | Coverage | Volume | Notes |
|---|---|---|---|
| Tímarit.is | Newspapers and periodicals, mostly pre-1920 | ~7M scanned pages, 1,975 titles | Web interface for search and browsing; bulk programmatic access is not officially provided1 |
| Bækur.is | Icelandic books from the start of printing to ~1900 | 2,980 titles, 3,618 volumes, ~710k pages | Launched 2010, operated by the National and University Library of Iceland; web interface only, same access model as Tímarit.is7 |
| Alþingi corpus | Parliamentary speeches, 1959–1988 | 47M running words | Used by the 2012 post-correction thesis5 |
| IGC-2024 | Modern Icelandic, mixed sources | ~1.4B words | Dataset card flags OCR artifacts in journal/newspaper subcorpora8 |
| MC-19 | Tímarit.is, 1800–1920 | 272M tokens, 317 sources | Includes ~18k tokens of gold-standard post-correction evaluation data3 |
| CLARIN-IS deposit | Real OCR'd line pairs | ~50k real + ~850k synthetic | Training data for post-correction models9 |
The biggest bottleneck is annotation. None of these resources ships with image–text pairs suitable for OCR evaluation: the post-correction deposits record corrected text without tracking which page image each line came from, so the existing evaluation data cannot be retrofitted into an OCR benchmark even in principle. I return to this in the dataset section.
Approach 1: Post-correction
Post-correction takes OCR output as input and tries to fix it. Formally, OCR is a conditional generation problem: given an image , find the most likely text :
Post-correction is a second conditional generation step on top of that output — given , find the corrected string :
The two are not the same optimization. A post-corrector is trained on pairs and has no access to ; it cannot recover information the recognizer lost at the image level. This is by far the most-studied approach for Icelandic.
The 2012 Alþingi thesis
The earliest substantial work I found is a thesis by Jón Friðrik Daðason in 2012 on Skemman (handle 1946/12085) applying post-correction to the Alþingi parliamentary digitization output.5 Two methods were used:
- A noisy-channel model for non-word errors: 92.9% correction accuracy.
- A Winnow classifier for real-word errors: 78.4% correction accuracy.
- Combined: 92.0% overall.
Notably, the OCR engine producing the input is not named or evaluated in the thesis. This framing, where OCR output is treated as a fixed upstream fact and correction is the research problem, set the pattern for subsequent work. Daðason also published a follow-up tool in 2014, based on a statistical error model and n-gram language model, which correctly identified and corrected 52.9% of errors on a separate evaluation set.10 That tool is the direct predecessor to Jasonarson et al. research "Generating Errors: OCR Post-Processing for Icelandic", which Daðason co-authored. His 2012 thesis advisor Kristín Bjarnadóttir co-authored the 2014 tool with him, and appears again as the author of the Database of Icelandic Morphology (DIM), which MC-19 relies on for its spelling normalization pipeline.3 This area of research has a tightly connected core group of individuals, consistently contributing to each others work over a considerable period.
The real-word category remains the hard residual for every subsequent system: inflectional density fills the word space densely enough that local correction without context is structurally insufficient.
The Language Technology Programme (2019–2023)
The first national language technology programme funded five core areas: language resources, Automatic Speech Recognition (ASR), Text-to-speech (TTS), machine translation (MT), and spell/grammar checking.11 OCR appeared as project L11, "Error models for OCR," and its output is the Jasonarson et al. (2023) paper along with a CLARIN-IS deposit of two trained transformer models and around 50,000 real annotated line pairs.29
The deposit's training corpus consists of roughly 900,000 total training lines, of which about 50,000 (5%) came from real OCR'd texts and the remainder were synthetic or surrogate. The deposit readme notes that increasing the real-data share would significantly improve the tool. As of writing, no follow-up has done so.
Synthetic error generation (Jasonarson et al., 2023)
Jasonarson et al. introduced a synthetic-data approach to address the scarcity of real corrected OCR text.2 They extracted error patterns from 375k tokens of manually corrected 19th-century text (80 texts, 1874–1913) using Python's SequenceMatcher, filtered to the 600 error types occurring more than three times, then inserted them into clean text with
-weighted frequency. This produced a ~7.8M-token training set combining real and synthetic parallel data, see Figure 1.
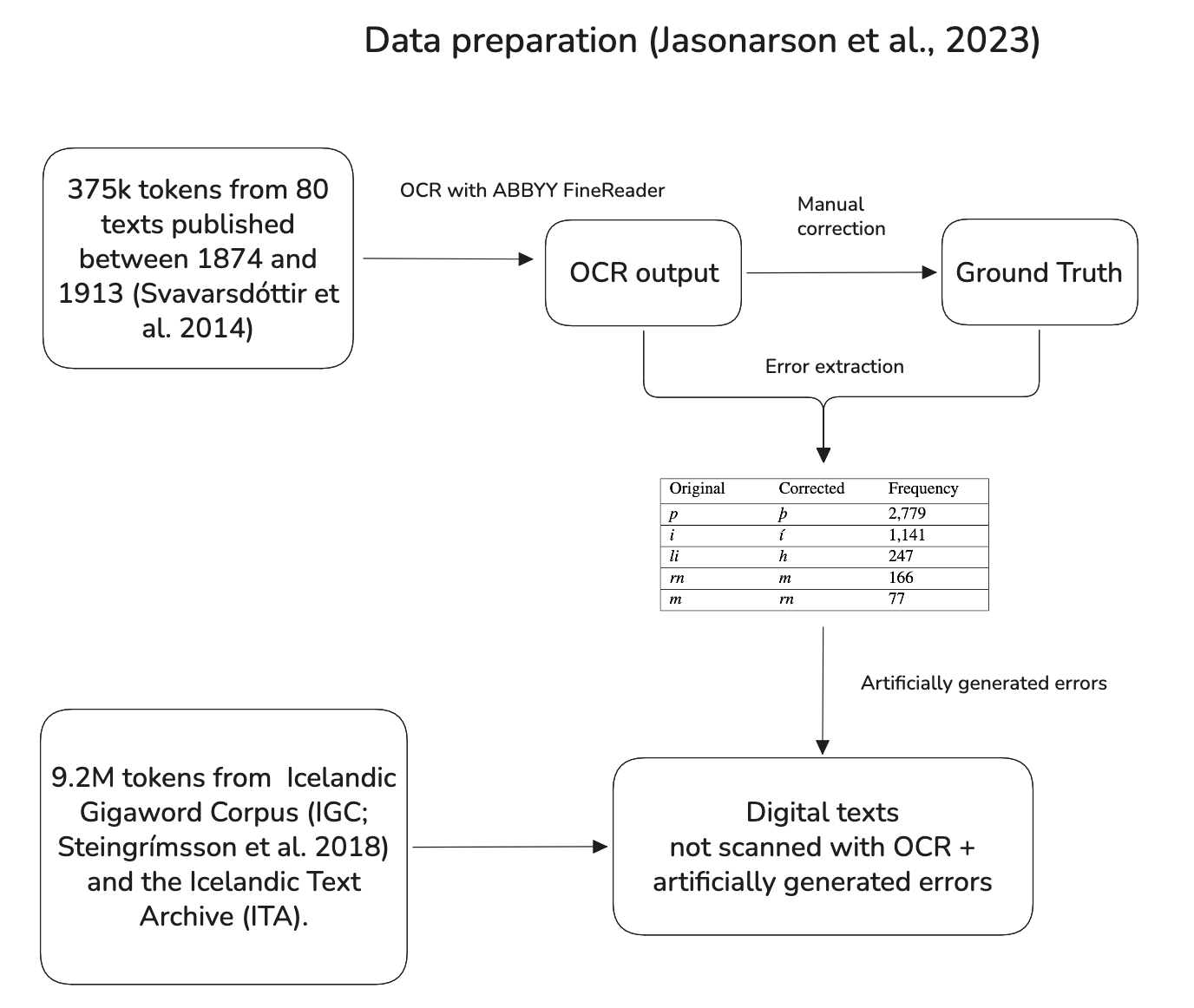
Six models were trained: four encoder-decoder transformers from scratch (two architectures, each trained with and without synthetic data) and two fine-tuned ByT5-base variants. On historical texts, the from-scratch models showed the largest gains from adding synthetic data: Model 1 went from 16% to 24% WERR (WER reduction, a relative metric), and Model 2 from 35% to 53% WERR. Fine-tuned ByT5 achieved the best absolute results overall (49.96% WERR on historical texts trained on real data only; 55.07% with synthetic augmentation), with a smaller relative gain from the synthetic data on historical texts, though a larger one on modern texts (+25 WERR points). MC-19 adopted the error extraction pipeline directly.
MC-19 (Steingrímsson et al., 2025)
The MC-19 paper applied the Jasonarson et al. pipeline to build a 272M-token corpus of 1800–1920 Icelandic text from Tímarit.is.3 Using a fine-tuned ByT5-base model — the same architecture as Jasonarson et al., trained on a combined dataset of approximately 4.2M tokens — they report 55.07% WER reduction on a manually corrected 18k-token evaluation set. The 6.49% baseline WER this figure is calculated from was established in Jasonarson et al.2
The MC-19 paper is also the source for the most direct statement in the literature about why post-correction has remained the dominant approach: the team chose to use the existing Tímarit.is OCR output rather than train their own OCR model, judging that doing so would be "resource intensive and not necessarily very beneficial".3 What makes this notable is not the decision itself but that it stands as the only published rationale for the dominant methodological orientation in the field, and it appears as a single sentence in a corpus paper, not as a considered argument.
Multilingual benchmarking (2024)
Guan & Greene (2024)12 tested four synthetic data generation methods for post-OCR correction across eight languages, including Icelandic. The method included random injection (injection random errors), image creation (rendering text as images, adding noise, then processing with a real OCR engine to obtain authentic-looking errors), real-world injection (similar to Jasonarson et al. but without the frequency weighting), and glyph similarity (substituting random characters with different similar characters, based on the shape of the character glyph). Their best method, glyph-similarity-based error injection, achieved a 17.94% CER reduction, second-worst in their evaluation ahead only of Irish.
This result is not directly comparable to MC-19's 35.12% CER reduction (and 55.07% WER reduction) because Guan & Greene trained on CC-100 web-crawled modern Icelandic and tested on Tesseract output from synthetic images, while the Icelandic work uses historical newspaper text with domain-specific error patterns. The paper attributes the weak result to proper-noun density in CC-100 and limited Icelandic representation in ByT5's pretraining. A third factor goes unnamed: their error generation was language-agnostic, using glyph similarity on a generic character set rather than errors extracted from real Icelandic OCR output. The Jasonarson et al. result suggests that gap matters.
The performance gap (35.12% CER reduction versus 17.94%) can't be pinned to a single variable, since the test sets differ. But the contrast is large enough to carry a practical conclusion: generic multilingual post-correction methods transfer poorly to Icelandic, and the error distribution of Tímarit.is OCR output is specific enough to reward domain-specific treatment.
Approach 2: Recognition-layer tools
Recognition-layer research is minimal, and the tools that do exist are not well-characterized on Icelandic test sets.
- Tesseract (
isl.traineddata) is the de facto recognition engine for Icelandic printed text and the upstream baseline for all post-correction work in this survey. The model is a synthetically-trained LSTM, rendered from Icelandic Wikipedia text using standard Latin fonts. There is no published standalone evaluation ofisl.traineddataon any Icelandic test set. The 6.49% WER reported in Jasonarson et al. is the closest thing to a baseline characterization, and it appears as a byproduct of a post-correction paper rather than a deliberate benchmark effort. MC-19's manual evaluation found it unusable on fraktur material.3 - Google Cloud Vision is used in CEMI for printed text; multilingual rather than Icelandic-specific.6
- Transkribus, a handwritten text recognition platform, has an Icelandic 19th-century HTR model built by the Centre for Digital Humanities and Arts (CDHA). The model is not publicly released.13
- CHURRO is a 3B-parameter open-weight VLM fine-tuned on 155 historical corpora spanning 46 language clusters, released in 2025.14 Icelandic is not in the evaluation set, but the model is openly available and represents the most credible recognition-layer alternative to Tesseract for historical print.
The recognition layer, in other words, is a Wikipedia-trained LSTM and three multilingual APIs. That is the entire toolkit for a language with millions of pages of unreadable historical print.
Datasets and evaluation
The state of evaluation data reveals the deepest structural gap in the field. Understanding it requires distinguishing two evaluation paradigms that the literature often treats as interchangeable:
- OCR evaluation requires image–text pairs: scanned page images paired with verified ground-truth text. The metric (CER/WER) measures the recognition system end-to-end.
- Post-correction evaluation requires OCR-output–corrected-text pairs: noisy text from an upstream OCR engine paired with manually cleaned text. The metric measures how much the corrector improves a fixed upstream output.
The two evaluations are not interchangeable. A model that does well on post-correction evaluation has not been evaluated as an OCR system; it has been evaluated as a downstream cleaner of one specific upstream pipeline.
The publicly available Icelandic resources are all of the second kind:
- MC-19 evaluation set: ~18,000 tokens of OCR-output text manually corrected against the original images, used to measure post-correction WER reduction. The published evaluation data is text-only; the source page images are not linked to the corrected lines.3
- CLARIN-IS deposit: ~50,000 line pairs of OCR'd and manually corrected text, used primarily as training data for post-correction models. The deposit contains
original/andcorrected/text directories; source page images are not included and the line pairs are not linked back to specific page images.9
I'm not aware of a public Icelandic image–text evaluation set for OCR. Setting aside the licensing question on Tímarit.is, the existing post-correction evaluation data cannot be retrofitted into an OCR benchmark, because the corrected text is not linked to specific source page images. An OCR benchmark for Icelandic would have to be built from scratch as an annotation effort, not assembled from existing artifacts.
Tímarit.is contains scans and machine-generated OCR text for nearly every Icelandic newspaper and periodical printed before 1920, but the archive is set up for human browsing, not bulk programmatic access, and its terms of use restrict the digital images to personal use.1 Building an OCR benchmark from this material is therefore both a permissions question and an annotation question.
For comparison, English OCR has standardized image–text benchmarks (ICDAR series,15 OmniDocBench,16 OlmOCR-Bench17) with thousands to millions of evaluation pages. The mismatch matters because it constrains what kinds of Icelandic OCR research can be evaluated rigorously: the field can compare post-correctors to each other, but it cannot directly compare recognition systems (Tesseract vs. Google Cloud Vision vs. a fine-tuned VLM) on a shared Icelandic benchmark.
Ongoing work
I've been working in this space and have published two HuggingFace datasets that may be useful as starting points for others:
Sigurdur/timarit-ocr: image–text pairs derived from Tímarit.is content.18Sigurdur/isl-finepdfs-images: Icelandic content extracted from a multilingual PDF dataset (HuggingFaceFW/finepdfs).19
Looking Forward
Icelandic OCR has a working post-correction pipeline and no benchmark to evaluate it against. That is roughly where the field stands.
The post-correction literature has made real progress on a specific and tractable problem: cleaning Tesseract output on 19th-century roman-type Icelandic newspaper text. The 55% WER reduction MC-19 reports is a meaningful result. But every paper in this survey optimizes on top of the same uncharacterized upstream baseline, and the methodological choice to treat recognition as a fixed fact rather than a research problem has never been argued for. It appears once, as a single sentence in a corpus paper.
With that in mind, the questions I think matter most for the field going forward:
- Are Tesseract
isl's errors on historical Icelandic print systematic enough to be learnable, or effectively arbitrary? The answer determines whether post-correction has a real ceiling problem. - Can synthetic training data substitute for annotated historical images at the recognition layer, or does the domain gap make it insufficient? The post-correction work suggests domain specificity matters considerably; whether the same holds one step earlier in the pipeline is open.
- Fraktur remains entirely unhandled. Would a multilingual fraktur model transfer to Icelandic with minimal adaptation, or does fraktur combined with archaic Icelandic orthography require dedicated data collection?
- How much do residual OCR errors in IGC-2024 and MC-19 degrade downstream language models trained on them? This is measurable in principle and unmeasured in practice.
- As VLMs increasingly handle print and handwriting through the same interface, does the two-problem split that has organized Icelandic work historically still make sense as a research boundary?
-
National and University Library of Iceland. Tímarit.is. https://timarit.is/about ↩︎ ↩︎ ↩︎
-
Jasonarson, A., Steingrímsson, S., Sigurðsson, E. F., Magnússon, Á. D., & Ingimundarson, F. Á. (2023). Generating Errors: OCR Post-Processing for Icelandic. Proceedings of the 24th Nordic Conference on Computational Linguistics (NoDaLiDa), 286–291. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
Steingrímsson, S., Sigurðsson, E. F., & Jasonarson, A. (2025). MC-19: A Corpus of 19th Century Icelandic Texts. Proceedings of the Joint 25th Nordic Conference on Computational Linguistics and 11th Baltic Conference on Human Language Technologies (NoDaLiDa/Baltic-HLT 2025), 680–687. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
Kargaran, A. H., Nikeghbal, N., Diesner, J., Yvon, F., & Schütze, H. (2026). GlotOCR Bench: OCR Models Still Struggle Beyond a Handful of Unicode Scripts. arXiv:2604.12978. https://arxiv.org/abs/2604.12978 ↩︎
-
Daðason, J. F. (2012). Post-Correction of Icelandic OCR Text [Vélræn leiðrétting á íslenskum ljóslesnum texta] (Master's thesis, supervised by Sven Þ. Sigurðsson and Kristín Bjarnadóttir). Skemman. https://skemman.is/handle/1946/12085 ↩︎ ↩︎ ↩︎
-
MSHL / Centre for Digital Humanities and Arts. Corpus of Early Modern Icelandic (CEMI). https://mshl.is/en/projects/early-modern-icelandic-corpus/ ↩︎ ↩︎
-
National and University Library of Iceland. Bækur.is. https://baekur.is/about ↩︎
-
Arnastofnun. IGC-2024: Icelandic Gigaword Corpus. HuggingFace. https://huggingface.co/datasets/arnastofnun/IGC-2024 ↩︎
-
CLARIN-IS deposit. OCR Post-Processing Tool for Icelandic 22.10. http://hdl.handle.net/20.500.12537/271 ↩︎ ↩︎ ↩︎
-
Daðason, J. F., Bjarnadóttir, K., & Rúnarsson, K. (2014). The Journal Fjölnir for Everyone: The Post-Processing of Historical OCR Texts. In Proceedings of Language Resources and Technologies for Processing and Linking Historical Documents and Archives – Deploying Linked Open Data in Cultural Heritage, pages 62–65, Reykjavik, Iceland. ↩︎
-
Sigurðsson et al. (2020). Language Technology Programme for Icelandic 2019–2023. Proceedings of LREC 2020, p. 418. ↩︎
-
Guan, S., & Greene, D. (2024). Advancing Post-OCR Correction: A Comparative Study of Synthetic Data. Findings of the Association for Computational Linguistics: ACL 2024, pages 6036–6047. arXiv:2408.02253v2. ↩︎
-
MSHL. Transkribus – Handwritten Text Recognition. https://mshl.is/en/projects/transkribus-htr/ ↩︎
-
Semnani, S. J., Zhang, H., He, X., Tekgürler, M., & Lam, M. S. (2025). CHURRO: Making History Readable with an Open-Weight Large Vision-Language Model for High-Accuracy, Low-Cost Historical Text Recognition. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 34777–34824. Association for Computational Linguistics. https://aclanthology.org/2025.emnlp-main.1763/ ↩︎
-
Karatzas, D., et al. ICDAR 2015 Competition on Robust Reading. Proceedings of the 13th International Conference on Document Analysis and Recognition (ICDAR), 2015. https://rrc.cvc.uab.es/ ↩︎
-
Ouyang, L., Qu, Y., Zhou, H., et al. (2024). OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations. arXiv:2412.07626. https://github.com/opendatalab/OmniDocBench ↩︎
-
Poznanski, J., Borchardt, J., Dunkelberger, J., et al. (2025). olmOCR: Unlocking Trillions of Tokens in PDFs with Vision Language Models. arXiv:2502.18443. https://arxiv.org/abs/2502.18443 ↩︎
-
Birgisson, S. H. timarit-ocr. HuggingFace. https://huggingface.co/datasets/Sigurdur/timarit-ocr ↩︎
-
Birgisson, S. H. isl-finepdfs-images. HuggingFace. https://huggingface.co/datasets/Sigurdur/isl-finepdfs-images ↩︎